

- A+
之前看过不少大佬的文章,提到nmap扫描准确,并且显示信息详细,但是速度太慢;masscan扫描快但是不会显示端口服务的相关信息,二者结合起来使用会有很不错的效果。后来经@罐罐大神邀请参加了济南defcon会议,在会上听@硬糖大神介绍了他设计这款扫描器的思路,于是想着自己以后有空也弄一版尝试一下。看过一些大佬们写的工具,很多都用到了数据库来存储扫描结果,我第一版只想弄一款高效易用的,存储结果就用txt保存了。
安装配置
我用的是python2.7版,首先需要下载masscan,下载地址:https://github.com/robertdavidgraham/masscan,需要安装编译,安装方法如下:
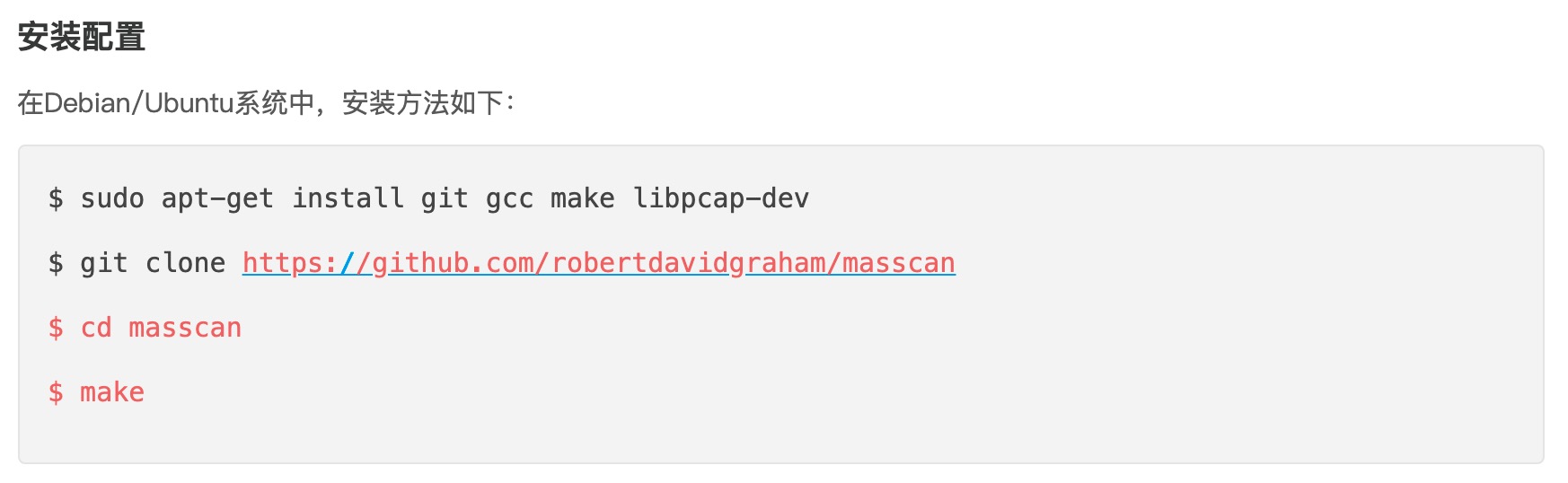
安装完成后的可执行程序在masscan/bin目录中。
代码逻辑
程序主要的逻辑是先从文本里读取目标ip列表,启用多线程扫描ip列表。扫描过程是先调用masscan扫描全端口,然后调用nmap进行端口服务识别,如果是web服务,把web的url、端口及title都打印出来;如果非web,只打印ip、端口及服务名称。
功能讲解
首先从文本中读取ip资产列表,启用多线程扫描,这里设置的是100线程,可以自己根据情况设定:

然后调用masscan进行端口扫描,这里要注意masscan的发包速率设置,如果设置过大漏报率会比较高,建议设置1000-2000,我这里设的是1000。masscan扫描完后会生成一个json文件,然后从中提取相关端口信息。这里参考了硬糖大神提到的扫描时遇到防火墙的问题,就是如果在扫描过程中发现目标主机几乎每个端口都开放,那说明很可能是有防火墙,这种情况可以设定一个端口数量阈值,超过阈值则直接跳过,扫描下一个ip(是的,目前就是跳过,就是躲开不搞的意思,以后再研究怎么硬搞),这里我设置的阈值是50:

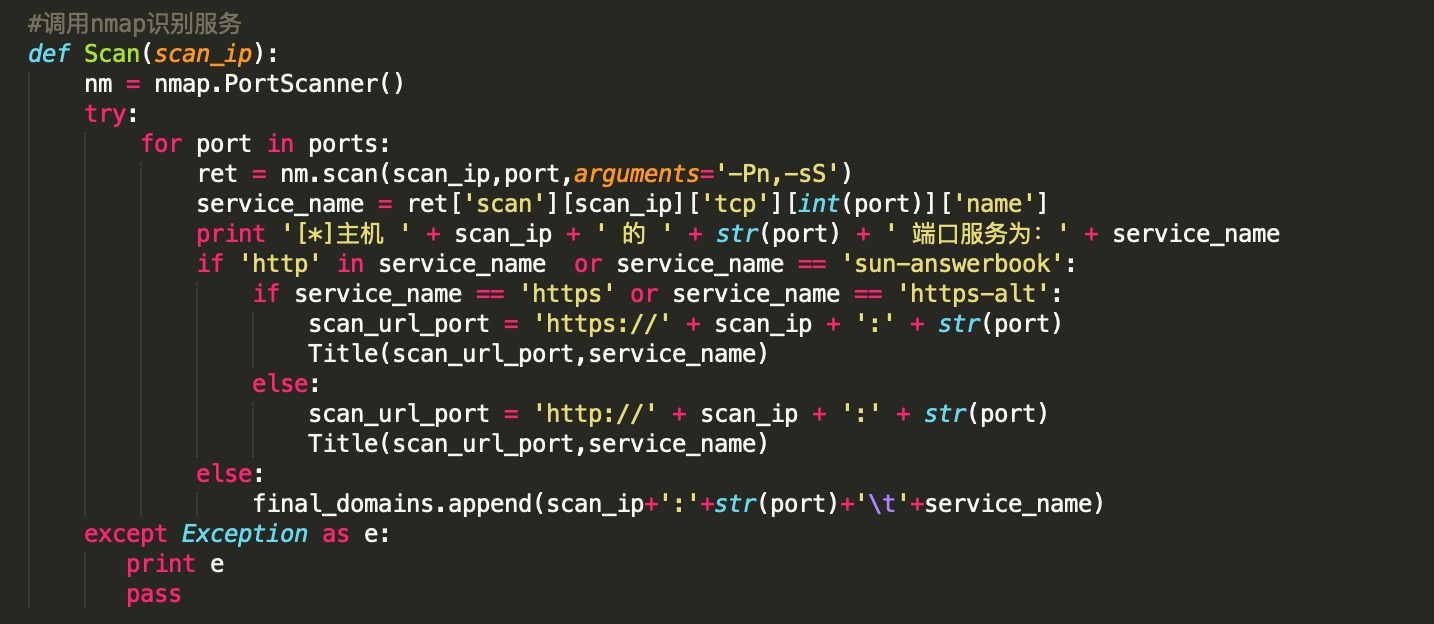
接下来调用nmap识别端口对应的服务,如果识别出来是web服务则通过Title函数来识别对应的网站title信息:
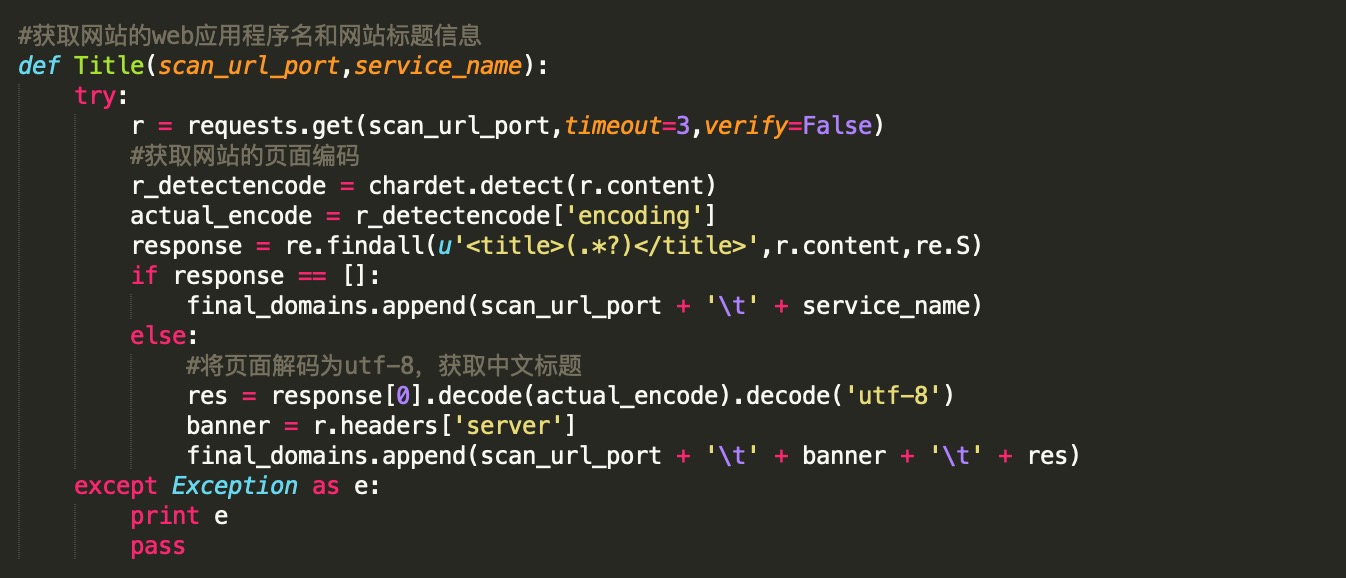
识别网站title信息这里我首先识别了网站采用的编码,因为如果不加识别直接按UTF-8或GBK来解码有时候会出错,只有识别了对应的编码才能有针对性地解码。另外这里之前遇到过获取到的网站标题为空列表,这样会报错,虽然能在页面打印出相关的web服务信息,但最后无法将web服务保存到扫描结果里,所以这里加了个if判断,在标题为空的情况下也将web服务信息保存下来:
最后将扫描结果进行一个去重处理,打印扫描所用的时间:

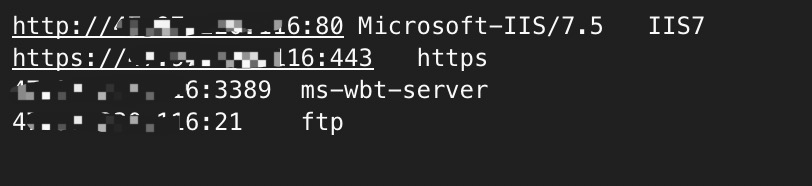
扫描结果
扫描结果大概如下所示:

此致敬礼
整个过程都是尽量使用了一些简单直接的方法,数据保存、去重等都没有在数据库层面进行操作。没有涉及usage提示,也没有杠这杠那的参数选项,是上来就干的这种类型。
这个是1.0版本,肯定会有诸多不足之处,后续会考虑加入一些复杂点的功能,希望大家能多批评指正。
代码已上传至github:https://github.com/hellogoldsnakeman/masnmapscan-V1.0
*本文作者:轩辕踏月留香,转载请注明来自FreeBuf.COM



