

- A+
大部分介绍机器学习的文章都使用众所周知的MNIST数据集手写数字识别(机器学习界的Hello World)开始,但通常我们处理的并不是图片作为输入,新手很难自己想象工程系统如何构建以及如何处理更复杂的特征。
今天这篇文章中的实验还将用作Ergo一些新功能的示例,Ergo是一个我与chiconara共同创建的自动机器学习模型创建、数据编码、GPU训练、基准测试和大规模部署的框架。关于本文使用的源代码都存储在此处。

值得注意的是,该项目不能有效地替代商业反病毒软件。
问题定义与数据集

传统的恶意软件检测引擎依赖于签名,这些签名是恶意软件分析人员提供的,在确定恶意代码的同时确保非恶意样本中没有冲突。
这种方法存在一些问题,这通常很容易被绕过(也取决于签名的类型,单个比特的改变或者恶意代码中几个字节的变更都可能导致无法检测),同时不利于大规模扩展。研究人员需要进行逆向工程分析,发现与写出独特的签名可能要数小时。
我们的目标是交给计算机,更具体地说是神经网络,来检测Windows恶意软件,而不依赖于任何需要显式创建的签名数据库。通过提供的恶意软件数据集,从数据集中学习如何区分恶意代码,最终应用在数据集外,最重要的是,要处理那些新的、未发现过的样本。我们唯一能提供的知识就是哪些文件是恶意的,哪些不是,但具体是如何区分的交给神经网络完成。
数据集收集了大约二十万个Windows PE样本,大概数量上恶意(VirusTotal超过十个检出)与非恶意(VirusTotal零检出)平分。由于在相同的数据集上训练和测试模型意义不大(在训练集上表现的非常好,但是对新样本不具有泛化能力),这个数据集被Ergo分为三个数据集:
训练集:占全部样本的70%,用于训练模型;
验证集:占全部样本的15%,在训练时用于校准模型;
测试集:占全部样本的15%,训练模型后比较模型效果。
毋庸置疑,数据集中标记正确的样本数量是模型准确的关键,这使得模型可以正确区分这两类样本,并推广到数据集外的样本。此外,理想情况下,应该使用较新的样本定期更新数据集,并对模型进行重新训练,以便发现新样本(wget+crontab+ergo)也能随着时间的推移保持高准确率。

由于这个数据集的规模大小限制,我们无法共享。但是我在Google云盘上传了一份dataset.csv文件,大约共340MB,你可以用这些数据来重现这篇文章的结果。
PE格式
Windows PE格式有记录丰富的文档,有很多很好的资源来理解内部格式定义,例如Ange Albertini在2013 44CON的讲稿:《探索PE格式》,看过这篇讲稿再看这篇文章可以获得很多前置知识:
PE包含几个头,描述其属性与各种关于寻址的细节,如PE在内存中加载的基址以及入口点的位置
PE包含几个段,包含数据(常量、全局变量等)、代码(该段被标记为可执行)等
PE包含导入的API与系统库的声明

例如,下图是Firefox PE段的示例:
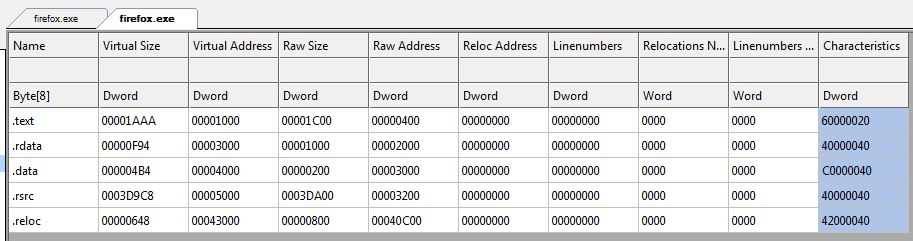
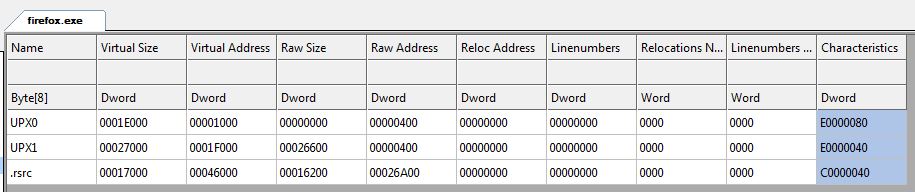
在某些情况下,如果PE已经使用诸如UPX之类的加壳程序进行处理,各段可能看起来和这个不太相同,因为代码和数据的部分都经过了压缩,并且添加了运行时脱壳的代码:
我们要做的是将这些异构的值编码为标量数据的向量,每个标量都在标准化区间[0.0,1.0]内,长度固定。这些是我们的机器学习模型能够理解的输入类型。
确定要提取PE哪些特征的过程可能是设计任何应用机器学习的系统中最重要的部分,读取这些值并对其进行编码的行为被称为特征工程。
特征工程
创建项目:
ergo create ergo-pe-av
在edcode.py中实现特征提取,这是一个非常简单的开始,但也提供了足够多的信息来达到一定的准确度,并且可以很容易地扩展功能。
cd ergo-pe-av
vim encode.py
设计的向量前十一个标量编码了一组布尔值,由QuarksLab开发的LIEF解析PE提取得出,每个属性为真则编码为1,如果为假则编码为0。
| 属性 | 描述 |
|---|---|
| pe.has_configuration | 如果PE加载配置文件 |
| pe.has_debug | 如果PE启用调试选项 |
| pe.has_exceptions | 如果PE使用Exception |
| pe.has_exports | 如果PE使用任意导出符号 |
| pe.has_imports | 如果PE导入任意符号 |
| pe.has_nx | 如果PE启用了NX位 |
| pe.has_relocations | 如果PE启用重定位 |
| pe.has_resources | 如果PE使用任意Resource |
| pe.has_rich_header | 如果存在一个Rich头 |
| pe.has_signature | 如果PE拥有数字签名 |
| pe.has_tls | 如果PE使用TLS |
然后的六十四个元素,代表PE入口点函数前的六十四个字节,每个元素都要进行归一化,这将会帮助模型检测那些具有独特入口点的可执行文件,这些入口点在相同家族的不同样本间仅有轻微的差别。
ep_bytes = [0] * 64
try:
ep_offset = pe.entrypoint - pe.optional_header.imagebase
ep_bytes = [int(b) for b in raw[ep_offset:ep_offset+64]]
except Exception as e:
log.warning("can't get entrypoint bytes from %s: %s", filepath, e)
# ...
# ...
def encode_entrypoint(ep):
while len(ep) < 64: # pad
ep += [0.0]
return np.array(ep) / 255.0 # normalize
然后是二进制文件中的ASCII表中每个字节重复次数的直方图,是有关文件原始内容的基本统计信息。
# 参数raw中有文件的全部内容
def encode_histogram(raw):
histo = np.bincount(np.frombuffer(raw, dtype=np.uint8), minlength=256)
histo = histo / histo.sum() # normalize
return histo
下一个特征是导入表,因为PE文件使用的API是非常有用的信息。为了做到这一点,我手动选择了数据集中150个最常见的库,每个PE使用相对应库的列值加一,创建另一个一百五十位的直方图,通过导入API的总量进行标准化。
# 参数pe为LIEF解析的PE对象
def encode_libraries(pe):
global libraries
imports = {dll.name.lower():[api.name if not api.is_ordinal else api.iat_address \
for api in dll.entries] for dll in pe.imports}
libs = np.array([0.0] * len(libraries))
for idx, lib in enumerate(libraries):
calls = 0
dll = "%s.dll" % lib
if lib in imports:
calls = len(imports[lib])
elif dll in imports:
calls = len(imports[dll])
libs[idx] += calls
tot = libs.sum()
return ( libs / tot ) if tot > 0 else libs # normalize
接下来使用磁盘上PE文件大小与内存大小(虚拟大小)的比率:
min(sz, pe.virtual_size) / max(sz, pe.virtual_size)
接下来,我们要使用关于PE段的信息,例如包含代码的段的数量与包含数据的段的数量,标记为可执行的段,每个段的平均熵值,大小与其虚拟大小的平均比率,这些数据会为模型提供该PE文件是否加壳/压缩/混淆的信息。
def encode_sections(pe):
sections = [{ \
'characteristics': ','.join(map(str, s.characteristics_lists)),
'entropy': s.entropy,
'name': s.name,
'size': s.size,
'vsize': s.virtual_size } for s in pe.sections]
num_sections = len(sections)
max_entropy = max(展开 for s in sections]) if num_sections else 0.0
max_size = max(展开 for s in sections]) if num_sections else 0.0
min_vsize = min(展开 for s in sections]) if num_sections else 0.0
norm_size = (max_size / min_vsize) if min_vsize > 0 else 0.0
return [ \
# code_sections_ratio
(len(展开]) / num_sections) if num_sections else 0,
# pec_sections_ratio
(len(展开]) / num_sections) if num_sections else 0,
# sections_avg_entropy
((sum(展开 for s in sections]) / num_sections) / max_entropy) if max_entropy > 0 else 0.0,
# sections_vsize_avg_ratio
((sum(展开 / s['vsize'] for s in sections]) / num_sections) / norm_size) if norm_size > 0 else 0.0,
]
最后,将这些所有零散的部分拼成一个486维的向量:
v = np.concatenate([ \
encode_properties(pe),
encode_entrypoint(ep_bytes),
encode_histogram(raw),
encode_libraries(pe),
[ min(sz, pe.virtual_size) / max(sz, pe.virtual_size)],
encode_sections(pe)
])
return v
剩下唯一需要做的就是告诉模型如何通过先前prepare.py中的函数来编码样本文件。如下所示,支持给定路径的文件编码、支持上传文件到Ergo API进行编码、支持原始向量进行编码:
# 使用`ergo encode <path> <folder>`编码PE文件为一个标量特征的向量
# 使用`ergo serve <path>`在推断前解析样本文件
def prepare_input(x, is_encoding = False):
# file upload
if isinstance(x, werkzeug.datastructures.FileStorage):
return encoder.encode_pe(x)
# file path
elif os.path.isfile(x) :
return encoder.encode_pe(x)
# raw vector
else:
return x.split(',')
现在就拥有了将样本转换为如下数据的能力:
0.0,0.0,0.0,0.0,1.0,0.0,0.0,1.0,1.0,0.0,0.0,0.333333333333,0.545098039216,0.925490196078,0.41568627451,1.0,0.407843137255,0.596078431373,0.192156862745,0.250980392157,0.0,0.407843137255,0.188235294118,0.149019607843,0.250980392157,0.0,0.392156862745,0.63137254902,0.0,0.0,0.0,0.0,0.313725490196,0.392156862745,0.537254901961,0.145098039216,0.0,0.0,0.0,0.0,0.513725490196,0.925490196078,0.407843137255,0.325490196078,0.337254901961,0.341176470588,0.537254901961,0.396078431373,0.909803921569,0.2,0.858823529412,0.537254901961,0.364705882353,0.988235294118,0.41568627451,0.0078431372549,1.0,0.0823529411765,0.972549019608,0.188235294118,0.250980392157,0.0,0.349019607843,0.513725490196,0.0509803921569,0.0941176470588,0.270588235294,0.250980392157,0.0,1.0,0.513725490196,0.0509803921569,0.109803921569,0.270588235294,0.250980392157,0.870149739583,0.00198567708333,0.00146484375,0.000944010416667,0.000830078125,0.00048828125,0.000162760416667,0.000325520833333,0.000569661458333,0.000130208333333,0.000130208333333,8.13802083333e-05,0.000553385416667,0.000390625,0.000162760416667,0.00048828125,0.000895182291667,8.13802083333e-05,0.000179036458333,8.13802083333e-05,0.00048828125,0.001611328125,0.000162760416667,9.765625e-05,0.000472005208333,0.000146484375,3.25520833333e-05,8.13802083333e-05,0.000341796875,0.000130208333333,3.25520833333e-05,1.62760416667e-05,0.001171875,4.8828125e-05,0.000130208333333,1.62760416667e-05,0.00372721354167,0.000699869791667,6.51041666667e-05,8.13802083333e-05,0.000569661458333,0.0,0.000113932291667,0.000455729166667,0.000146484375,0.000211588541667,0.000358072916667,1.62760416667e-05,0.00208333333333,0.00087890625,0.000504557291667,0.000846354166667,0.000537109375,0.000439453125,0.000358072916667,0.000276692708333,0.000504557291667,0.000423177083333,0.000276692708333,3.25520833333e-05,0.000211588541667,0.000146484375,0.000130208333333,0.0001953125,0.00577799479167,0.00109049479167,0.000227864583333,0.000927734375,0.002294921875,0.000732421875,0.000341796875,0.000244140625,0.000276692708333,0.000211588541667,3.25520833333e-05,0.000146484375,0.00135091145833,0.000341796875,8.13802083333e-05,0.000358072916667,0.00193684895833,0.0009765625,0.0009765625,0.00123697916667,0.000699869791667,0.000260416666667,0.00078125,0.00048828125,0.000504557291667,0.000211588541667,0.000113932291667,0.000260416666667,0.000472005208333,0.00029296875,0.000472005208333,0.000927734375,0.000211588541667,0.00113932291667,0.0001953125,0.000732421875,0.00144856770833,0.00348307291667,0.000358072916667,0.000260416666667,0.00206705729167,0.001171875,0.001513671875,6.51041666667e-05,0.00157877604167,0.000504557291667,0.000927734375,0.00126953125,0.000667317708333,1.62760416667e-05,0.00198567708333,0.00109049479167,0.00255533854167,0.00126953125,0.00109049479167,0.000325520833333,0.000406901041667,0.000325520833333,8.13802083333e-05,3.25520833333e-05,0.000244140625,8.13802083333e-05,4.8828125e-05,0.0,0.000406901041667,0.000602213541667,3.25520833333e-05,0.00174153645833,0.000634765625,0.00068359375,0.000130208333333,0.000130208333333,0.000309244791667,0.00105794270833,0.000244140625,0.003662109375,0.000244140625,0.00245768229167,0.0,1.62760416667e-05,0.002490234375,3.25520833333e-05,1.62760416667e-05,9.765625e-05,0.000504557291667,0.000211588541667,1.62760416667e-05,4.8828125e-05,0.000179036458333,0.0,3.25520833333e-05,3.25520833333e-05,0.000211588541667,0.000162760416667,8.13802083333e-05,0.0,0.000260416666667,0.000260416666667,0.0,4.8828125e-05,0.000602213541667,0.000374348958333,3.25520833333e-05,0.0,9.765625e-05,0.0,0.000113932291667,0.000211588541667,0.000146484375,6.51041666667e-05,0.000667317708333,4.8828125e-05,0.000276692708333,4.8828125e-05,8.13802083333e-05,1.62760416667e-05,0.000227864583333,0.000276692708333,0.000146484375,3.25520833333e-05,0.000276692708333,0.000244140625,8.13802083333e-05,0.0001953125,0.000146484375,9.765625e-05,6.51041666667e-05,0.000358072916667,0.00113932291667,0.000504557291667,0.000504557291667,0.0005859375,0.000813802083333,4.8828125e-05,0.000162760416667,0.000764973958333,0.000244140625,0.000651041666667,0.000309244791667,0.0001953125,0.000667317708333,0.000162760416667,4.8828125e-05,0.0,0.000162760416667,0.000553385416667,1.62760416667e-05,0.000130208333333,0.000146484375,0.000179036458333,0.000276692708333,9.765625e-05,0.000406901041667,0.000162760416667,3.25520833333e-05,0.000211588541667,8.13802083333e-05,1.62760416667e-05,0.000130208333333,8.13802083333e-05,0.000276692708333,0.000504557291667,9.765625e-05,1.62760416667e-05,9.765625e-05,3.25520833333e-05,1.62760416667e-05,0.0,0.00138346354167,0.000732421875,6.51041666667e-05,0.000146484375,0.000341796875,3.25520833333e-05,4.8828125e-05,4.8828125e-05,0.000260416666667,3.25520833333e-05,0.00068359375,0.000960286458333,0.000227864583333,9.765625e-05,0.000244140625,0.000813802083333,0.000179036458333,0.000439453125,0.000341796875,0.000146484375,0.000504557291667,0.000504557291667,9.765625e-05,0.00760091145833,0.0,0.370786516854,0.0112359550562,0.168539325843,0.0,0.0,0.0337078651685,0.0,0.0,0.0,0.303370786517,0.0112359550562,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0561797752809,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0449438202247,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,1.0,0.25,0.25,0.588637653212,0.055703845605
假设你有一个包含恶意样本的文件夹pe-malicious与非恶意样本的文件夹pe-legit,你可以开始处理样本进行编码到dataset.csv中,然后用于模型训练:
ergo encode /path/to/ergo-pe-av /path/to/dataset --output /path/to/dataset.csv
需要一些时间,具体需要多长时间视数据集大小与磁盘速度而定,总之要持续一段时间才能结束。
向量的有用属性
趁着Ergo正在对数据集进行编码,趁机讨论一下有用属性与如何使用这些属性。
结构上、行为上相似的可执行文件应该具有相似的向量。测量两个向量之间的距离/差异的方式很多,例如通过余弦相似度:
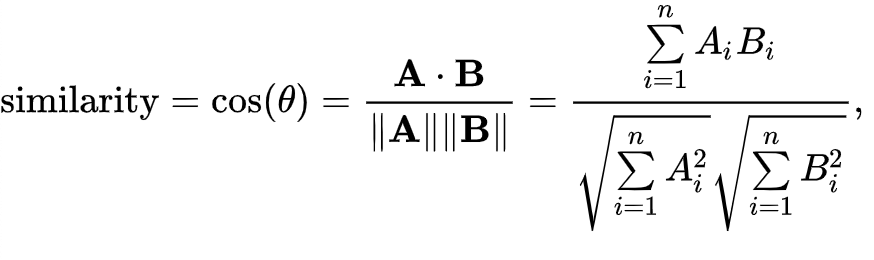
该度量标准可以在给定数据集中确定一个已知家族的基准样本。例如,已有MIPS的Mirai样本文件,希望从数千个不同的、未标记的样本中提取不同体系结构下的Mirai变体。
在sum数据库中执行名为findSimilar的存储过程来实现该算法是很简单的:
// 根据 id 指定向量,返回余弦相似度大于等于阈值的其他向量列表
// 结果作为 "vector_id => similarity" 式样的字典给出
function findSimilar(id, threshold) {
var v = records.Find(id);
if( v.IsNull() == true ) {
return ctx.Error("Vector " + id + " not found.");
}
var results = {};
records.AllBut(v).forEach(function(record){
var similarity = v.Cosine(record);
if( similarity >= threshold ) {
results[record.ID] = similarity
}
});
return results;
}
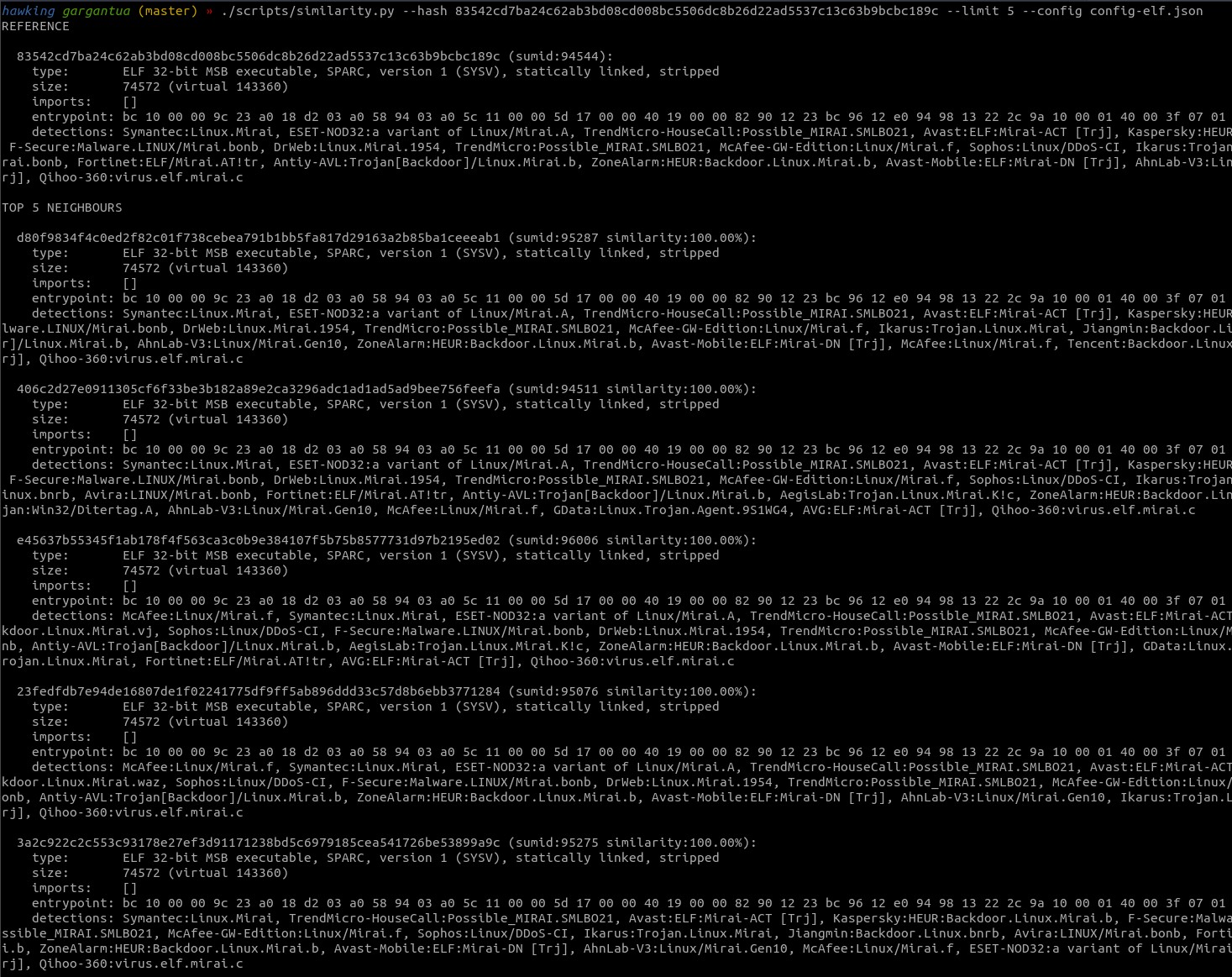
虽然简单,但效果很好:
神经网络训练
编码器完成工作后,dataset.csv中应该包含从每个样本中提取的所有向量,这个结果文件可以用来训练模型。但是“训练模型”意味着什么?
模型是被称为神经网络的计算结构,使用Adam优化算法进行训练。进一步了解可以获得更多详细的定义,但此时只需要知道的是,神经网络是一个“盒子”,包含数百个数值参数(“神经元”的权重,按层组织),它们与输入(我们提供的向量)相乘并组合产生输出预测。训练过程包括向系统提供数据集,根据已知标签检查预测结果。少量更改参数,查看这些变化是否影响模型的准确性,并重复此过程指定的次数(epochs),直到整体性能达到所定义的最小值。
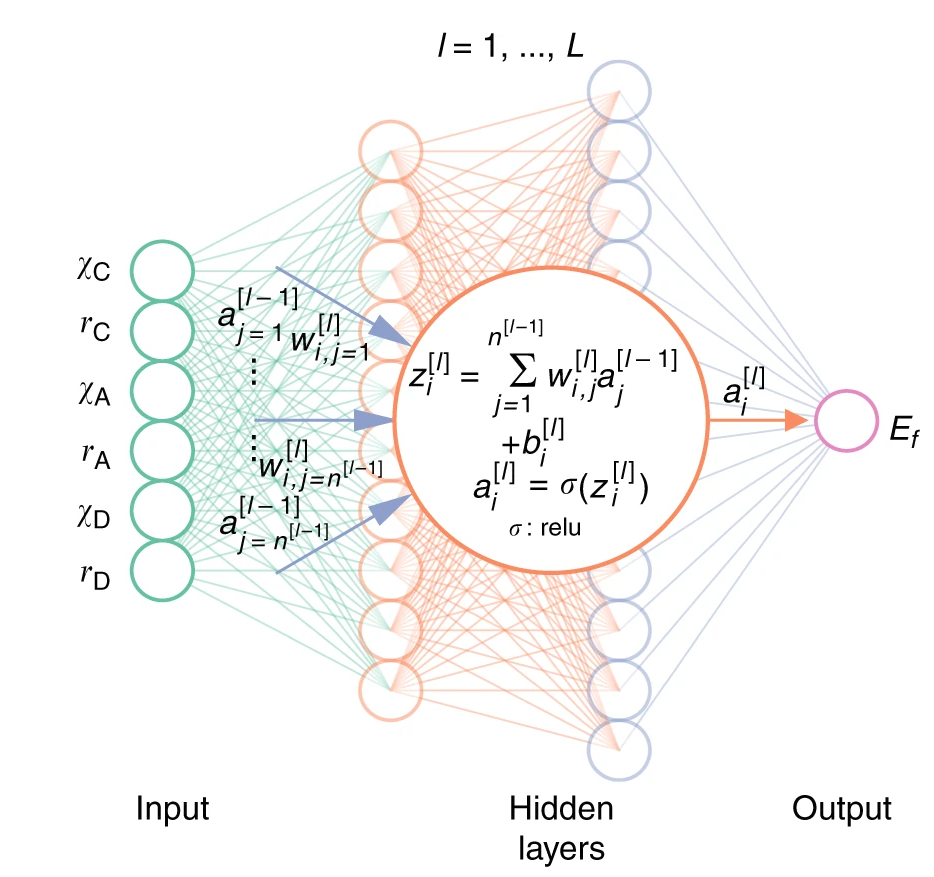
主要假设是数据集中的数据点之间存在数值关联,但我们并不知道。如果是已知的,可以直接通过这种关联关系求解输出。我们要做的是要求黑盒提取数据集特征并通过迭代调整其内部参数来近似这样的函数。
在model.py文件中,可以找到神经网络的定义,这是一个全连接网络,每个隐藏层包含70个神经元,ReLU作为激活函数,在训练时dropout率为30%。
n_inputs = 486
return Sequential([
Dense(70, input_shape=(n_inputs,), activation='relu'),
Dropout(0.3),
Dense(70, activation='relu'),
Dropout(0.3),
Dense(2, activation='softmax')
])
现在可以开始启动训练:
ergo train /path/to/ergo-pe-av /path/to/dataset.csv
根据CSV文件中向量总数量的不同,该过程可能需要持续几分钟到几天不等。如果设备支持GPU,ergo会自动使用GPU代替CPU提升训练的速度,如果想进一步了解,可以查看这篇文章。
完成后,可以使用以下方式检查模型性能统计信息:
ergo view /path/to/ergo-pe-av
从中可以看出训练的过程,可以检查模型的准确性是否确实随着时间的推移而增加,我们的例子中在30代左右达到了97%的准确度。ROC曲线会显示模型如何有效地区分恶意与否(AUC或曲线下面积为0.994,意味着模型非常好)。

![]()
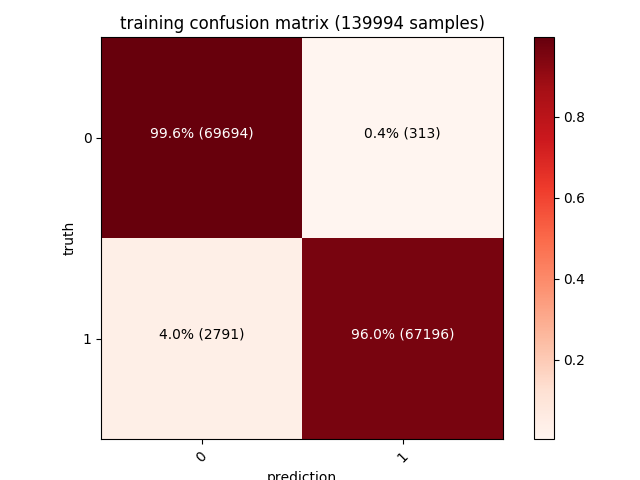
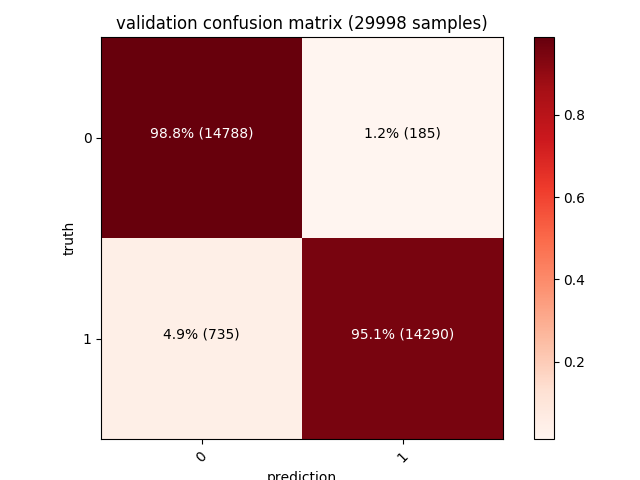
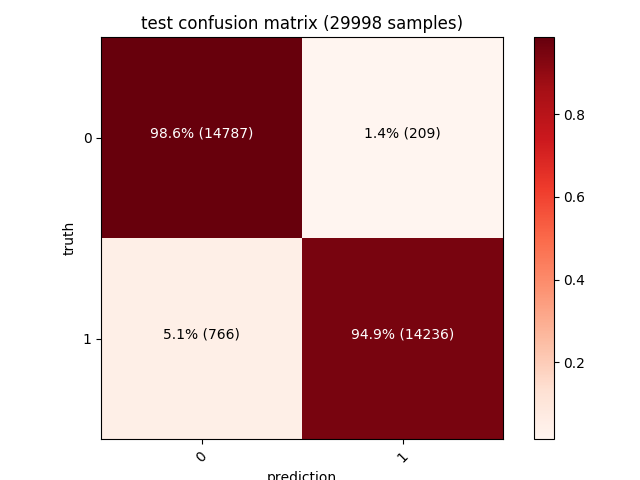
此外,还可以显示每次训练、验证与测试集的矩阵。左上角的对角线值(深红色)表示正确预测的数量,而其他值(粉红色)表示错误的数量,我们的模型在三万个样本的测试集上具有1.4%的误报率。
![]()
考虑到特征提取算法的简单,这样一个大规模数据集取得97%的准确度是一个很不错的结果。许多错误都是由UPX(或者只是自解压ZIP/MSI文件)这样的加壳程序引起的,这些程序会影响我们正在编码的一些数据点,进一步添加脱壳策略(模拟脱壳直到真正的PE文件被加载到内存中)、加入更多功能(更大的入口点矢量、动态分析跟踪被调用的API),是提高准确率的关键。
结论
完成后可以删除临时文件:
ergo clean /path/to/ergo-pe-av
加载模型并将其用作API:
ergo serve /path/to/ergo-pe-av --classes "clean, malicious"
此时进行分类的话:
curl -F "x=@/path/to/file.exe" "http://localhost:8080/"
可以收到如下响应,可对比该文件的VirusTotal结果:
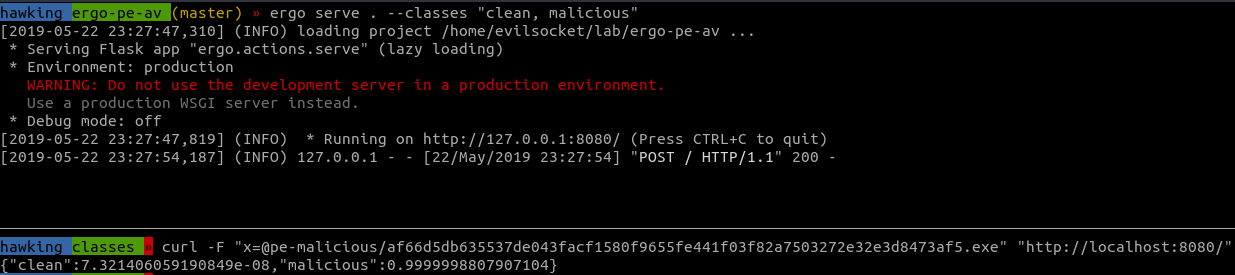
现在可以使用该模型进行想要的文件扫描了!

![]()
*参考来源:evilsocket,FB小编Avenger编译,转载请注明来自FreeBuf.COM



